
Related Articles



In this article, you’ll learn about the Anatomy of Reinforcement Learning and Supervised Learning in Artificial Intelligence & Strategies of Reinforcement Learning.
Introduction:
- In this blog, you are going to learn related to java development services about an entirely new paradigm of machine learning and machine intelligence. The leading experts in the world open AI and deep mind have created AIs that can master even newer and more complex games such as Quake III, Dota 2 etc. but reinforcement learning does not stop at video games.
- Techniques such as simulation will accelerate AI because robots learning from simulation don’t take any damage. They won’t break and we won’t need to build them again.
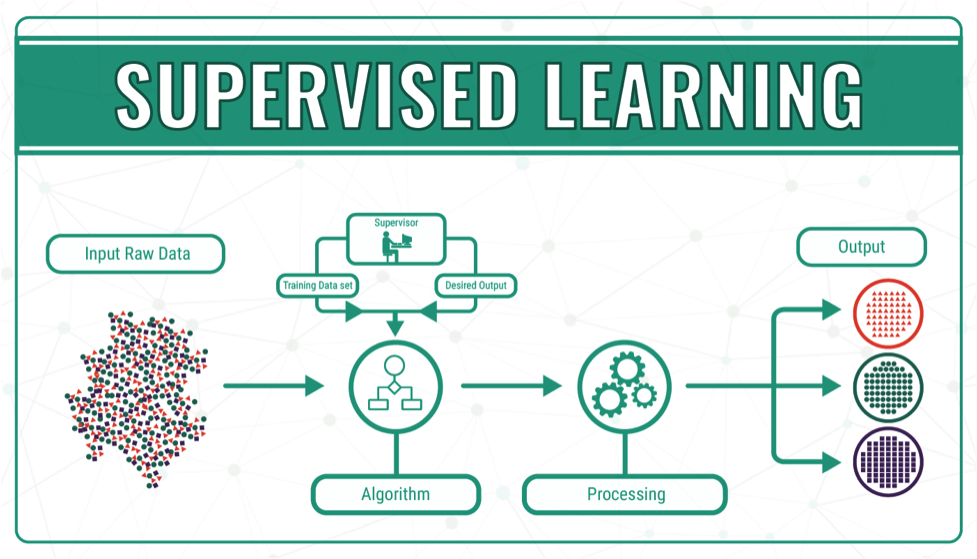
Reinforcement Learning Anatomy:
Reinforcement learning is way different than supervised and unsupervised learning. But supervised learning and unsupervised learning aren’t that different.

Supervised Learning Examples:-
- Spam Detection – When an email arises in the inbox the email application tries to classify whether it is spam or not.
- Image Classification- To determine what kind of object are there in a given image.
Unsupervised Learning Examples: –
- Clustering genetic sequence – One can determine the ancestry of different families or different types of animals
- Topic modelling web process – In a given set of documents one can determine which documents discuss the same and similar topics.

Reinforcement learning Example: –
- Playing strategic games such as Chess & Go.
- Playing any advance type video games such as Doom or Star craft
So, as I mentioned in the above examples portray how and what reinforcement does things which is similar to things that humans can do in a very dynamic way. And if we compare this with the supervised and unsupervised learning, then we will find it more like a very static and simplistic task and these are unchanging.
Supervised/Unsupervised Interfaces
- For the supervised and unsupervised learning, the interface is always same in both the cases and these are modeled and based upon around the psyche learn. We will always have the same fit() function for a supervised learning interface and this function takes two arguments X and Y where X is input samples and Y is Target.
Class of Supervised Model :
def fit(X, Y) :
def predict(X):
- As you can see above, a supervised interface usually includes the fit() and predict() method with the arguments as X and Y. For fit(X, Y), I have already mentioned what is X and Y and now for predict function, X represents the input samples and it usually try to predict Y value accurately. Now have a look below to see what it takes for an Interface of unsupervised learning.
class of Unsupervised Model:
def fit(X) :
def transform(X) :
- In unsupervised Learning interface, it usually contains a fit()method of java development services i.e. is used for taking the input samples X as one and only one argument and there is no Y argument for this method which represents targets in case of unsupervised learning. In some cases, there is another function used called transform() function which takes one and only one argument X which is nothing but some input samples and then it turns it into Z and where Z is completely a different representation post the transformation. The better example for this would be returning a mapping to some cluster identity or returning a mapping to some vector.
- The main point is that supervised and unsupervised learning are actually so similar that it makes sense to put them in the same library in the first place. And it makes sense for their eyes to take on this very simple and neat format.
- The common theme of both of these is that the interface to these is training data
- Input training data either x and y or just X and you call a fit function
- Input data will be X (N × D matrix)
- Data X and target Y are very simple X is just an end by the matrix of input data and Y is just an N length vector of targets
- The generic format doesn’t change whether you’re doing biology finance economics etc
- Fits most of the algorithms in one neat library called Sci kit-Learn
- It’s very simplistic but still it’s very useful.
- Using these algorithms one can do face detection so that one can unlock the phone and speech recognition so that one can talk to the phone
Reinforcement Learning Agent:
- It can guide and agent for how to act in the world. So, the reinforcement learning Agent interface is not just limited to data instead it is broader than that. It would be better to say that interface to a reinforcement learning Agent can be the entire the real-world environment or can be the simulated environment in case of Video Games.
- Just to give an example, I can say that a reinforcement learning agent can be created which can learn the walking process. In the defense world, advance military system is also interested in RL agents which would be capable enough to replace the soldiers or military force not only for learning walking but also in other severe activities like diffusing bombs and learning to fighting and in making important and quick decisions during any mission period (Example can be vacuum robot).
- As already you are aware that in RL, the interface much more broad than just data and can be the real-world environment.
- The agent is going to have sensors some cameras some microphones and accelerator a G.P.S and so on.
- It is a continuous stream of data coming in and it’s constantly reading this data to make a decision about what to do in that moment.
- It has to take into account both past and future. It doesn’t just statically classify or label things.
- In other words a Reinforcement Learning agent is a thing which has a lifetime and in each and every step of its lifetime,a decision has to be made about what to do a static supervised or unsupervised model is not like that it has no concept of time because if someone will give an input then it will give a corresponding output.
Supervised Algorithm Example
The Supervised algorithm should be able to solve reinforcement learning tasks
- X can represent the state I’m in, Y represents the target (ideal action to perform in that state)
- But consider game like GO: N = 8 ×10100possible board position
- Image Net, the image classification benchmark has N = 106 images
- The number of samples per go would be 94 orders of magnitude larger than an image that which can take about one day to train with a good hardware
- If you give some idea about one order of magnitude larger it would take 10 days to train
- If you give some idea about two order of magnitude larger it would take 100 days to train
- If you give 94 order of magnitude larger then it would take
- The A.I can’t play the same role in same way every single time because everybody wants to allow creativity and stochastic behavior
- A supervise model even if it were feasible to train would only have one target per input so it would never be able to do human like things like say generate poetry
Supervised Targets & Rewards
- Sometimes the references to psychology; RL has been used to model animal behavior
- RL agent’s goal is in the future: In contrast, a supervised model simply tries to get good accuracy / minimize cost on the current input
- Feedback signals (rewards) come from the environment (i.e. the agent experiences them)
- Supervised targets/labels as something like rewards but these handmade labels are coded by humans- they do not come from environment
- Supervised inputs/ targets are just database tables
- Supervised models are instantly known if it is wrong/right, because inputs + targets are provided simultaneously
- RL is dynamic – if an agent solves a maze, it only knows its decisions were correct if it eventually solves the maze
Unexpected Strategies of Reinforcement Learning:
- Expanding the idea of a goal or future goal phrasing the objectives in terms of goals allows us to solve a much wider variety of problems. The goal of Alpha Go is to win go the goal of a video game. Artificial intelligence is to either get as far as possible in the game without dying or archive a high score. When you consider animals and specially human’s evolutionary psychologists have said that the genes are selfish all they want to make more of themselves.
- However human beings are conscious, so they behave in the way they do because of a deeper underlying desire they’re unaware of. That desire is our genes to procreate. If someone talks to your gene or ask them how they feel about not entities, you would normally consider having any feelings in the usual sense and yet it’s been theorized that everything you do is only for the benefit of your genes. You are simply a vessel for gene’s proliferation. According to some theory consciousness is just an illusion. There is a disconnect between what you think you want vs. “true goal”.
- This is really very interesting because like Alpha Go, we’ve roundabout and unlikely ways of achieving our goal. Experts commented that Alpha Go use some surprising and unusual techniques. The action i.e. taken doesn’t necessarily have to have an obvious/explicit relationship to the goal in hand. For example, you might desire to be reach and earn more money and then why so?
- Perhaps those with a specific set of genes that are related to desire to be rich ended up being prominent in our gene pool due to natural selection. Being healthy and having social status may be the result of being rich and this in turn helps in replicating the genes there by maximizing the central goal.
- Being rich and replication of genes can never be governed by any laws of physics that exists in since. How many years you are going to leave or being healthy to what extent which means measuring your health conditions: these are all can be the novel solution to the problem. So, similarly, Artificial Intelligence is capable to find such unusual and complex methods of solving real-time problem or finding or obtaining a goal
- “getting/being rich” can be replaced with any of the traits we want
- By Remaining healthy and string
- With strong analytical skill
- Our interest always lies in the fact where for achieving the same goal, there can be multiple novel strategies for example in case of gene replication as I already explained above. and these strategies are always fluctuating in time. So, one thing to notice here is that suppose reinforcement algorithm finds a better strategy that may appear to work in your case right now, but that does not really prove that it is globally optimal solution or optimal strategy. For example, the dose of Alcohol or desire for Sugar. Alcohol can be treated as medicine in a very little dosage and same way, Sugar gives energy but more alcohol or more Sugars Today causes disease and death)
Seed of the learning and adaptation
- Animals gain new traits via evolution/mutation/natural selection
- This is slow
- Each new born, even given an advantageous trait, still must learn from scratch
- AI can train via stimulation
- It can spawn new offspring instantly
- Obtain hundreds/thousands of years of experience in the blink of an eye
Bandit Problems to Reinforcement Learning
- Let’s look at the banner problem but from a slightly different strategy with different terminology. The basic analogy in the bandit problem is that you are playing a bunch of slot machines and you are trying to decide which arm to pull.
- At this point, we are going to make things more abstract. Instead of replying on an analogy which will never actually be used in real life, we are going to start using terminology i.e. more like what we use in full reinforcement learning.
The first concept is that of an action.
Actions
- The first terminology is that of an “action”.
- Referred as “pulling the slot machine arm” which is now simply called as action.
- Action is something that you do or the agent does
- If there are two advertisements, then there will be three possible actions
- Action can also be continuous (torque applied to motor, steering angle)
Expanding the example (Online Ads)
- Previously, all users treated equally
- Most probably an older person would be interested in an advertising for home than a teenager who doesn’t have any concept of owing home.
- A single click through rate is insufficient
Contextual Bandit:
So basically, contextual information is used in decision making process. It based on features such as previous websites visited.In some cases, it might have true and explicit information where perhaps the user entered that information themselves. In addition, things like time of the day of the week might matter your location in the world might matter.
States:
It’s a pretty generic term so it might take some getting used to but in general idea of state is very flexible. As mentioned previously it can represent attributes of user end of the world itself like the time and position but in more general terms it can represent any measurement made by a computer.
Examples:
An online advertising system:
- State = (time, day, zip code, gender, age, occupation)
A temperature controller:
- State= (temperature, humidity)
- Using machine learning: We can use “machine learning” to account for state
X: feature representation of state
W: model parameters
Ŷ= wT x: expected reward
Y= true reward
- As an example of how to build an algorithm to take into account the state in order to decide an action to maximize reward, we can use machine learning.
- Let’s x represent as a feature vector, w as parameters or weight, then from study of linear regression take the dot product of x and w to get a predicted reward. To compare the predicted reward y hat to the true award that eventually get called y and then use the error between the two to update the model in particular the weight vector w.
Difference between the examples

State = (time, day, zip code, gender, age, occupation)
State= (temperature, humidity)
The difference between a state vector representing the attributes of a user is; in one case the sequence of states that depend on one another and in other case they don’t.
State Sequences:
You can find more examples where states are interconnected:
- Temperature / humidity: If you are looking at the temperature or humidity of the room, there is more certainly some structure in the sequences of observations that will help you to determine how to control heating and cooling.
- Stock prices: Can’t determine “up”/ “down from a single snapshot rather the sequence of stock prices. Because we are interested in things like is the stock price is going up or down and obviously, we do not know whether something is going up or down from just a single price.
- Board games (chess/ go): The state of the board like where each of the pieces will be dependent where they were previously, and they’ll have a strong effect on where they are in future.
So, I hope you are getting here some idea that there are some environments where it is not just the state by itself that matters but rather the sequence of states.
Conclusion:
Here, in this blog, I have explained the very basic fundamentals of Reinforcement Learning (RL) in the areas of Machine Learning where and how the agent learns to make a sequence of decisions to achieve a certain goal. Also, I have mentioned about the strategies of RL and the supervised algorithm example.
FAQs:
Subject: Reinforcement Learning & Contextual Bandit
- What is the difference between supervised and unsupervised machine learning?
- What is the significance of contextual bandit in Reinforcement learning?
- How state sequence plays a role in deciding the optimal outcome in real-time scenario?
- What are the unexpected strategies of RL (Reinforcement learning)?
- What is the main difference between supervised and reinforcement learning?
- Give a supervised algorithm example and how it can solve the reinforcement learning task?
